

Most innovation teams jump straight into RICE scoring or some variation of impact/effort matrices without realizing their evaluators are operating on completely different mental scales. One person's "high impact" is another's "medium." One evaluator's "feasible" means "we could start tomorrow," while their colleague thinks it means "technically possible within two years."
This disconnect creates problems that compound over months. Ideas that should never make it past initial screening get greenlit because three evaluators misaligned on what "strategic fit" actually meant. Meanwhile, genuinely transformative concepts die in committee because nobody calibrated on what constitutes acceptable risk.
Teams rarely discover these misalignments until after launching initiatives that consume resources and deliver underwhelming results. By then, the damage extends beyond wasted budget—it erodes trust in the entire innovation process.
Why standard frameworks break down in practice
RICE works beautifully in theory. Reach times Impact times Confidence divided by Effort gives you a clean prioritization score. Simple math, clear winner emerges. Except real evaluation sessions look nothing like the textbook examples.
Picture your typical quarterly planning session. Marketing proposes an AI chatbot integration. Operations suggests warehouse layout optimization. Product wants to rebuild the mobile experience. Finance pushes for automated reconciliation. Each team member unconsciously anchors their scoring to their departmental context. The marketing director rates everything through a customer acquisition lens. The COO filters through operational efficiency. Nobody explicitly states these biases, but they shape every score assigned.
Strategic fit becomes particularly problematic. Without concrete anchoring, evaluators default to pattern matching against their past experiences. Someone who worked at a hypergrowth startup rates aggressive expansion ideas higher. The person from a traditional enterprise favors incremental improvements. Both believe they're scoring objectively against company strategy.
Economic impact suffers from similar distortion. Revenue-generating ideas automatically score higher than cost-reduction initiatives, even when the cost savings deliver superior net value. Direct revenue feels more tangible than prevented losses or efficiency gains.
Feasibility assessments reveal another layer of dysfunction. Technical feasibility, resource availability, organizational readiness, and market timing all collapse into a single score. An idea might be technically straightforward but require political capital the organization lacks. Another might demand technical complexity but align perfectly with existing initiatives. The composite feasibility score obscures these critical distinctions.
Teams rarely notice these differences until after they've launched initiatives that underperform, by which point the cost is real and trust in the process is low.
The calibration exercise that changes everything
Before touching any scoring sheets, run this calibration session with your evaluation team. It takes ninety minutes but saves months of misaligned execution.
Capture, evaluate, and act on ideas without friction.
GoIdeafy streamlines the entire innovation lifecycle from idea submission to implementation.
- Centralized idea capture
- Collaborative evaluation tools
- Progress tracking & analytics
No credit card required
Start with historical examples from your own organization. Pull three successful initiatives and three failures from the past eighteen months. Have each evaluator independently score these known outcomes using your proposed rubric. Don't reveal which were successes or failures yet.
The spread in scores will shock you. That product launch everyone considers a massive success? Half your team scores it as medium impact while others rate it transformational. The initiative that nearly bankrupted a division? Some evaluators mark it as highly feasible based on incomplete information.
Now reveal the actual outcomes and facilitate discussion. Why did Jennifer rate the failed mobile app as highly feasible when it crashed three times during beta? Because she evaluated technical feasibility while Marcus considered market readiness. Neither was wrong—they operated from different definitions.
Create anchor points from this discussion. That successful product launch becomes your benchmark for "8 out of 10" economic impact. The failed mobile app defines what "3 out of 10" feasibility looks like when considering full-stack readiness, not just technical possibility.
Document these anchors with specific characteristics:
Strategic Fit Anchors:
-
Score 9-10
Directly advances primary strategic objective, CEO personally championing
-
Score 7-8
Aligns with two strategic pillars, has executive sponsor
-
Score 5-6
Supports strategic direction, no direct opposition
-
Score 3-4
Tangential connection, requires narrative gymnastics to justify
-
Score 1-2
Contradicts current strategy or diverts resources from strategic initiatives
Economic Impact Anchors:
-
Score 9-10
Generates or saves >$2M annually, validated by finance
-
Score 7-8
$500K-2M annual impact, clear measurement path
-
Score 5-6
$100-500K impact, some assumptions required
-
Score 3-4
<$100K impact or highly speculative returns
-
Score 1-2
Negligible financial impact or net negative ROI
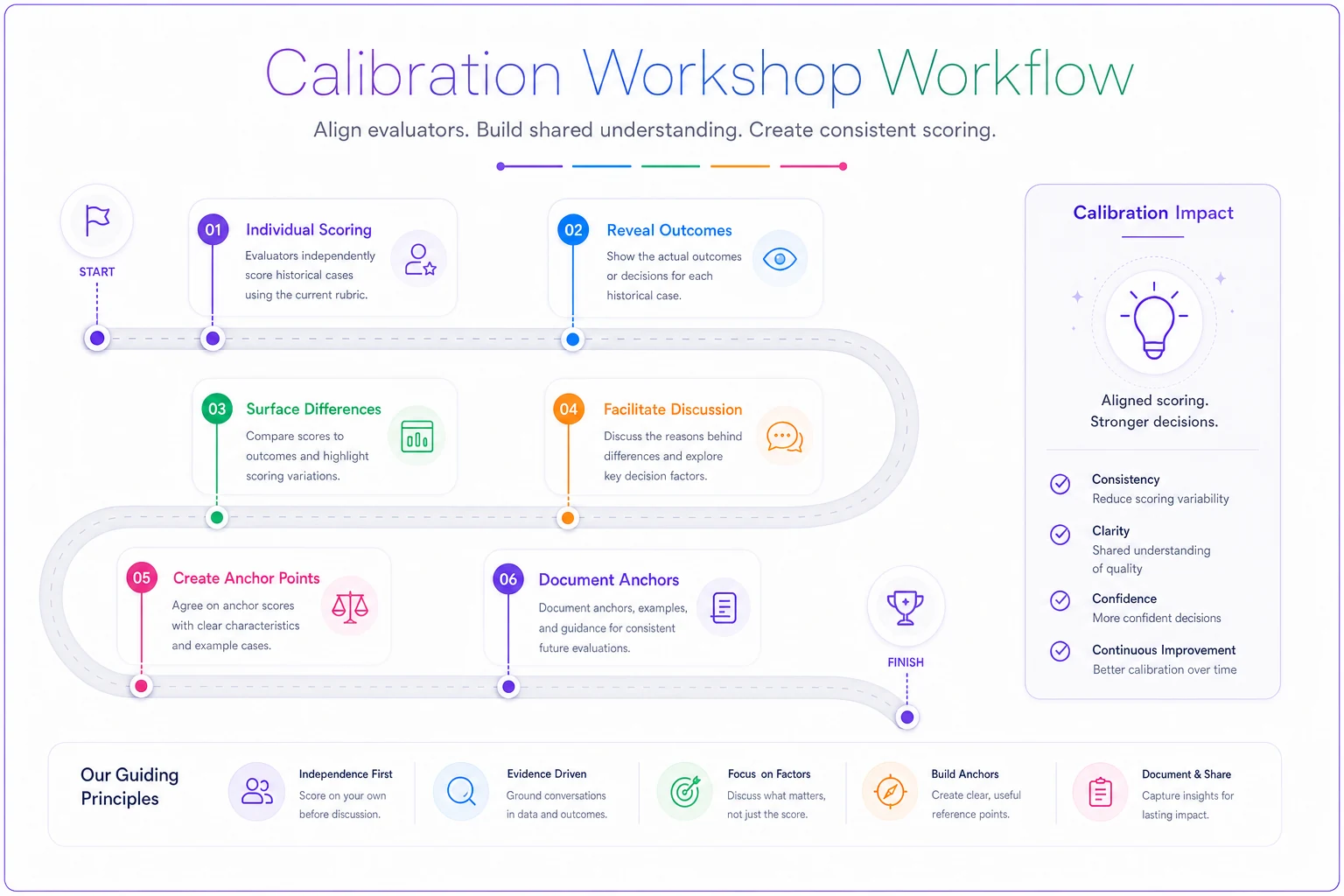
A simple visual like this clarifies the steps for new evaluators and keeps the team aligned.
Building evaluation criteria that actually stick
Generic criteria produce generic results. Your rubric needs specificity that reflects your organization's unique context and constraints.
Start with strategic fit, but define it through your actual strategy documents, not abstract concepts. If your three-year plan emphasizes geographic expansion, operational excellence, and digital transformation, then strategic fit means explicitly supporting one of these pillars. An idea that improves customer experience might sound strategic, but if it doesn't ladder up to your documented priorities, it scores low on strategic fit.
Economic impact requires graduated scales with clear thresholds. Avoid vague descriptors like "significant revenue increase" or "moderate cost savings." Instead, establish concrete ranges based on your organization's scale. A startup might consider $50K significant while an enterprise needs $5M to move the needle.
For feasibility, separate technical and organizational readiness into distinct scores. Technical feasibility examines whether you can build or implement the solution with existing capabilities plus reasonable learning curve. Organizational feasibility assesses political capital required, change management complexity, and cultural alignment. An idea might be technically trivial but organizationally impossible, or vice versa.
Equity deserves its own dimension, especially for consumer-facing innovations. Who benefits from this idea? Who might be excluded? Does it widen or narrow accessibility gaps? A premium feature that only serves high-value customers scores differently than one that democratizes access to core functionality.
Consider this scoring table structure:
| Dimension | Weight | Scoring Approach | Bias Check |
|---|---|---|---|
| Strategic Fit | 30% | Match against 3 documented priorities | Evaluator must cite specific strategy section |
| Economic Impact | 25% | Graduated scale with dollar ranges | Require finance validation for scores >7 |
| Technical Feasibility | 15% | Current capability vs. required capability | Engineering lead must review scores >8 |
| Organizational Feasibility | 15% | Change management complexity scale | HR assessment for ideas affecting >50 people |
| Equity & Access | 15% | Inclusion impact assessment | Diversity committee spot-check quarterly |
Require finance validation for scores >7 to reduce optimistic economic impact estimates.
Make sure weights reflect trade-offs your organization cares about and align with where you plan to allocate resources.
Tactical bias-mitigation during evaluation
Even with calibrated criteria, cognitive biases creep into scoring sessions. The halo effect makes exciting ideas seem more feasible. Recency bias overweights similar ideas that recently succeeded or failed elsewhere. Confirmation bias leads evaluators to score ideas higher when they align with preconceived beliefs about what the organization needs.
Implement these tactics during actual evaluation sessions:
-
Blind initial scoring Evaluators score ideas without knowing who proposed them. Strip identifying information and department origins. This prevents political calculations and relationship dynamics from influencing scores.
-
Sequential revelation Present ideas in stages. First, show only the problem statement and have evaluators assess strategic fit. Then reveal the proposed solution and score feasibility. Finally, share projected outcomes for economic impact scoring. This prevents impressive outcomes from creating a halo effect that inflates other dimensions.
-
Devil's advocate rotation Assign one evaluator per idea to argue against it, regardless of their actual opinion. They must identify hidden costs, implementation risks, and reasons for failure. This systematic negativity balances natural optimism bias.
-
Reference class forecasting Before scoring economic impact, identify three similar initiatives from other organizations. What did they actually achieve versus projections? This grounds estimates in empirical reality rather than aspirational thinking.
-
Scoring revision rounds After initial scoring, share the distribution of scores without revealing who gave what score. If strategic fit scores range from 3 to 9, facilitate discussion about what each evaluator sees. Allow score adjustments after discussion, but track how much scores shift.
Large shifts indicate initial misalignment.
The worksheet that keeps everyone honest
Create evaluation worksheets that force concrete thinking rather than gut reactions. Each dimension needs specific prompts that prevent lazy scoring.
For strategic fit questions:
-
Which specific strategic objective does this support? (cite document and page)
-
What currently funded initiative would this replace or complement?
-
How does this idea accelerate our strategic timeline?
For economic impact questions:
-
What comparable initiative generated similar returns?
-
Which assumptions could cut projected impact by 50%?
-
How do we measure success at 3, 6, and 12 months?
For feasibility questions:
-
What's the riskiest technical component?
-
Which three stakeholders could block this?
-
What capability would we need to build or buy?
For equity questions:
-
Who cannot access this solution and why?
-
Does this widen or narrow existing gaps?
-
What unintended exclusions might occur?
Make evaluators complete these prompts before assigning numerical scores. The written justification reveals fuzzy thinking and forces precision. When someone rates feasibility as 9 but writes "might need some new systems," the disconnect becomes obvious.
Running effective calibration sessions
Quarterly calibration keeps your evaluation system sharp. Don't wait for annual planning cycles—by then, mental models have drifted too far apart.
Schedule 90-minute sessions:
First 20 minutes: Review recent evaluation outcomes. Which highly-scored ideas underperformed? Which low scorers surprised everyone? This retrospective grounds the discussion in reality.
Next 30 minutes: Score three new test cases together. Use real ideas that won't be evaluated formally. Watch for divergence in real-time and discuss immediately.
Next 30 minutes: Update anchor points based on new evidence. That idea you scored 8 for feasibility that turned into a nightmare? It becomes your new anchor for overconfidence in feasibility scoring.
Final 10 minutes: Document refinements to scoring criteria. Small adjustments compound into major improvements over time.
Track calibration metrics:
-
Standard deviation of scores (should decrease over time)
-
Correlation between scores and actual outcomes
-
Time required to reach consensus
-
Number of post-launch surprises
Use these metrics to measure whether your calibration work is actually improving alignment and predictive power over time.
When sophisticated scoring makes sense (and when it doesn't)
This level of evaluation rigor isn't universal. A five-person startup iterating rapidly needs lightweight decision-making, not complex rubrics. But specific situations demand sophisticated evaluation infrastructure.
You need robust scoring when:
-
innovation budget exceeds $1M annually
-
multiple departments compete for limited innovation resources
-
failed initiatives could damage market position
-
regulatory or compliance issues demand documented decision-making
-
board and investors require systematic innovation governance
You're overengineering if:
-
evaluation takes longer than initial ideation
-
scoring debates replace actual experimentation
-
perfect scores matter more than rapid learning
-
the rubric hasn't changed in two years
-
everyone games the system successfully
Match the level of rigor to the risk and scale of the decisions you're making.
Automating bias detection without losing human judgment
Modern evaluation platforms can flag statistical anomalies that suggest bias. When one evaluator consistently scores 2 points higher than the team average, that pattern needs investigation. When ideas from certain departments systematically score lower, unconscious bias might be operating.
AI-powered operational software can track scoring patterns and surface these insights without replacing human judgment. The system identifies when an evaluator's scores deviate significantly from historical patterns or peer assessments. It compares projected scores against similar past initiatives, flagging when optimism seems unwarranted.
But automation works best as a complement, not replacement. The software surfaces patterns and anomalies. Humans investigate why those patterns exist and whether they reflect legitimate differences in perspective or problematic biases.
Some patterns appear problematic but have valid explanations. The engineering director might consistently rate technical feasibility lower because they understand hidden complexity others miss. The sales leader might accurately assess market readiness better than internal teams. The key is distinguishing expertise from bias.
Beyond scoring: Creating evaluation culture
The best evaluation rubric fails if organizational culture doesn't support honest assessment. When political pressure overrides scores, when "pet projects" bypass evaluation, when negative assessments damage careers—the system breaks down regardless of sophistication.
Build evaluation culture through consistent practices. Celebrate people who accurately identify risks, not just champions of successful ideas. Share stories of ideas that scored poorly, got killed, and saved the organization from expensive mistakes. Make "good judgment" part of performance reviews, measuring accuracy of assessments over time.
Create psychological safety around negative evaluations. The person who rates an idea as unfeasible shouldn't fear retaliation from the idea's champion. Anonymous scoring helps but isn't sufficient. Leadership must explicitly protect and reward honest assessment.
Close the feedback loop. Track actual outcomes against predicted scores. Share this data broadly. When the idea everyone loved flames out, discuss why scores missed reality. When the dark horse succeeds, understand what evaluators overlooked. This continuous learning makes every evaluation cycle more accurate than the last.
Making it sustainable
The most sophisticated evaluation system means nothing if teams abandon it after two quarters. Sustainability requires balancing rigor with practicality.
Start with lighter-weight evaluation for smaller ideas. Not every concept needs full scoring across all dimensions. Create tiers - quick experiments under $10K get a simple feasibility check, pilot programs between $10-100K need strategic fit and feasibility scoring, major initiatives over $100K get the full rubric with calibration.
-
quick experiments under $10K get a simple feasibility check
-
pilot programs between $10-100K need strategic fit and feasibility scoring
-
major initiatives over $100K get the full rubric with calibration
Rotate evaluation responsibilities to prevent burnout. The same five people scoring every idea leads to fatigue and degraded quality. Build a bench of trained evaluators who participate periodically.
Keep documentation lightweight but searchable. Recording extensive justification for every score creates overhead that kills adoption. Capture enough context to understand decisions six months later, not enough to defend them in court.
Review and refine the system quarterly, but resist constant tweaking. Major changes should happen annually based on accumulated evidence, not knee-jerk reactions to single failures.
The goal isn't perfect scoring—it's consistently better decision-making than gut instinct alone. When your evaluation system catches even half the ideas that would have failed, when it surfaces just a few dark horses that transform the business, when it reduces political innovation theater by 30%—that's massive value.
Your idea evaluation rubric becomes a competitive advantage when it helps you pick winners others miss and avoid losers others chase. That only happens when you move beyond generic frameworks to build evaluation systems that match your specific context, actively combat cognitive biases, and continuously improve through calibration.
The teams getting this right aren't necessarily smarter or more innovative. They've just built better filters for separating signal from noise in the endless stream of ideas competing for resources. In innovation, what you choose not to do matters just as much as what you pursue. A calibrated, bias-resistant evaluation rubric ensures you're making those choices based on evidence rather than enthusiasm.
Ready to transform your innovation process?
Join 2,000+ companies using GoIdeafy to unlock team creativity, prioritize impactful ideas, and accelerate growth.